Can You Trust AI with a MIT Exam?
March 2026
TL;DR
We administered 270 problem-set and exam questions drawn from two MIT courses to ten frontier language models, scoring each response on correctness and mathematical rigor. OpenAI’s o3 achieved the highest accuracy at 92.1% and was the only model whose self-reported confidence fell below its actual performance — a property we term well-calibration. Nine of ten models were substantially overconfident, with gaps between stated certainty and true accuracy ranging from 5 to 48 percentage points. A secondary evaluation on 102 student essays found that no model reached human-level inter-rater agreement, and that the models ranking highest on quantitative reasoning did not rank highest on subjective writing assessment. Taken together, the results suggest that the central challenge for deployed AI is not raw accuracy but the reliable communication of uncertainty.
We administered every problem set and practice examination from two MIT courses to ten frontier language models, covering MIT 8.033 (Special and General Relativity, Fall 2025) and 6.1220 (Design and Analysis of Algorithms, Fall 2023). Each model received a single-turn prompt, the official formula sheet, and an instruction to show its derivation steps and report a confidence score. No multi-turn interaction, external tools, or hints were permitted.
The corpus comprised 270 questions, yielding 2,700 individual model responses and approximately 6.8 million tokens of output. Each response was graded by an automated judge on two independent dimensions: correctness, scored on a 0–3 scale, and mathematical rigor, scored on a 0–2 scale, for a combined maximum of 5 points per question. A separate evaluation asked each model to predict human-assigned scores for 102 student essays drawn from the Kaggle Automated Essay Scoring 2.0 dataset, enabling a direct comparison of quantitative reasoning ability and subjective language judgement.
This work is a publication of Trust, a company building tools that help people understand when AI output can be relied upon. The question motivating this benchmark is not simply whether models can solve hard problems, but whether the signals models emit alongside their answers constitute genuine evidence about the reliability of those answers.
270
MIT-level questions
10
frontier models tested
6.8M
tokens analyzed
| STEMEval Benchmark v2.0 — MIT 8.033 + 6.1220 — 270 questions · 2,700 API calls · 6,824,025 tokens | ||
|---|---|---|
| Place | Model | Accuracy |
| 1st | o3 | 92.1% |
| 2nd | Gemini 2.5 Pro | 89.4% |
| 3rd | o4-mini | 88.2% |
| Best Overall: o3 · Best Value: Gemini 2.5 Flash ($0.31) · Fastest: GPT-4o | ||
Contents
- 1.The Leaderboard
- 2.Finding 1: The Confidence Calibration Crisis
- 3.Finding 2: The 74x Cost Paradox
- 4.Finding 3: GPT-4o Is Inventing Physics
- 5.Finding 4: Physics Reveals What Algorithms Don't
- 6.Finding 5: Rigor Is Structurally Load-Bearing
- 7.Finding 6: Models Can Compute. They Can't Think About Physics.
- 8.Beyond Physics: AI as Essay Grader
- 9.What This Means for AI Trust
- 10.Methodology
- 11.Citation
The Leaderboard
Measured accuracy spans 42 percentage points across the ten models evaluated, ranging from o3 at 92.1% to DeepSeek-R1 at 50.9%. The problem corpus was drawn from MIT 8.033 (Special and General Relativity, Fall 2025) and 6.1220 (Design and Analysis of Algorithms, Fall 2023), representing genuine undergraduate coursework rather than purpose-built benchmark items.
| Rank | Model | Accuracy | Avg Rigor | Cost (full eval) | Hallucinations |
|---|---|---|---|---|---|
| 1 | o3 | 92.1% | 1.95 / 2.0 | $5.31 | 0 |
| 2 | Gemini 2.5 Pro | 89.4% | 1.90 / 2.0 | $5.40 | 1 |
| 3 | o4-mini | 88.2% | 1.89 / 2.0 | $2.22 | 0 |
| 4 | Gemini 2.5 Flash | 85.4% | 1.85 / 2.0 | $0.31 | 2 |
| 5 | GPT-4.1 | 83.0% | 1.75 / 2.0 | $3.03 | 1 |
| 6 | Claude Opus 4 | 81.8% | 1.69 / 2.0 | $23.11 | 2 |
| 7 | Claude Sonnet 4 | 79.5% | 1.70 / 2.0 | $4.88 | 5 |
| 8 | Grok-3 | 73.6% | 1.45 / 2.0 | $11.13 | 4 |
| 9 | GPT-4o | 60.1% | 1.24 / 2.0 | $2.51 | 11 |
| 10 | DeepSeek-R1 | 50.9% | 1.01 / 2.0 | $1.99 | 0 * |
* DeepSeek-R1 produced no hallucinated formulas because it declined to respond to 123 of 270 questions (45.6%). Abstention precludes both correct answers and formula fabrication.


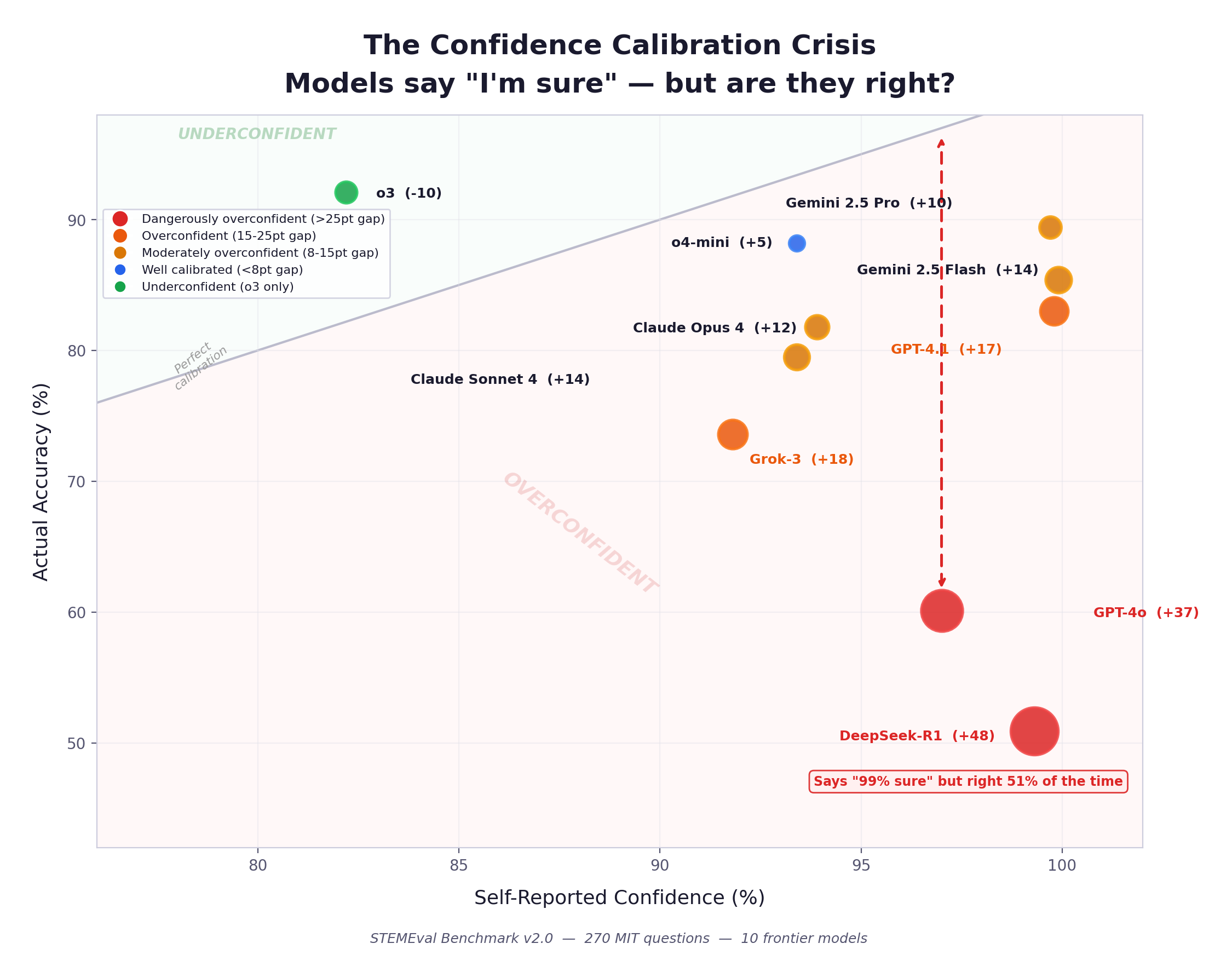
The Confidence Calibration Crisis
This is the finding that matters most for anyone deciding whether to trust AI output.
We asked each model to self-report its confidence after answering. The results reveal a near-universal failure mode: almost every model is dramatically overconfident. When a model says “I’m 99% sure,” it should be right 99% of the time. The gap between that claim and reality is the trust gap.
| Model | Self-Reported Confidence | Actual Accuracy | Gap | Trust Signal |
|---|---|---|---|---|
| DeepSeek-R1 | 99.3% | 50.9% | −48.4 pts | Broken |
| GPT-4o | 97.0% | 60.1% | −36.9 pts | Broken |
| GPT-4.1 | 99.8% | 83.0% | −16.8 pts | Degraded |
| Grok-3 | 91.8% | 73.6% | −18.2 pts | Degraded |
| Claude Sonnet 4 | 93.4% | 79.5% | −13.9 pts | Degraded |
| Claude Opus 4 | 93.9% | 81.8% | −12.1 pts | Degraded |
| Gemini 2.5 Flash | 99.9% | 85.4% | −14.5 pts | Degraded |
| Gemini 2.5 Pro | 99.7% | 89.4% | −10.3 pts | Degraded |
| o4-mini | 93.4% | 88.2% | −5.2 pts | Acceptable |
| o3 | 82.2% | 92.1% | +9.9 pts | Well-Calibrated |
o3 is the only model whose self-reported confidence falls below its actual accuracy. Every other model in the evaluation exhibits overconfidence of varying severity. The practical consequence is substantial: a system that reports 99.3% certainty while achieving 50.9% accuracy is supplying downstream consumers with confidence signals that are not merely imprecise but systematically inverted in their informational value.
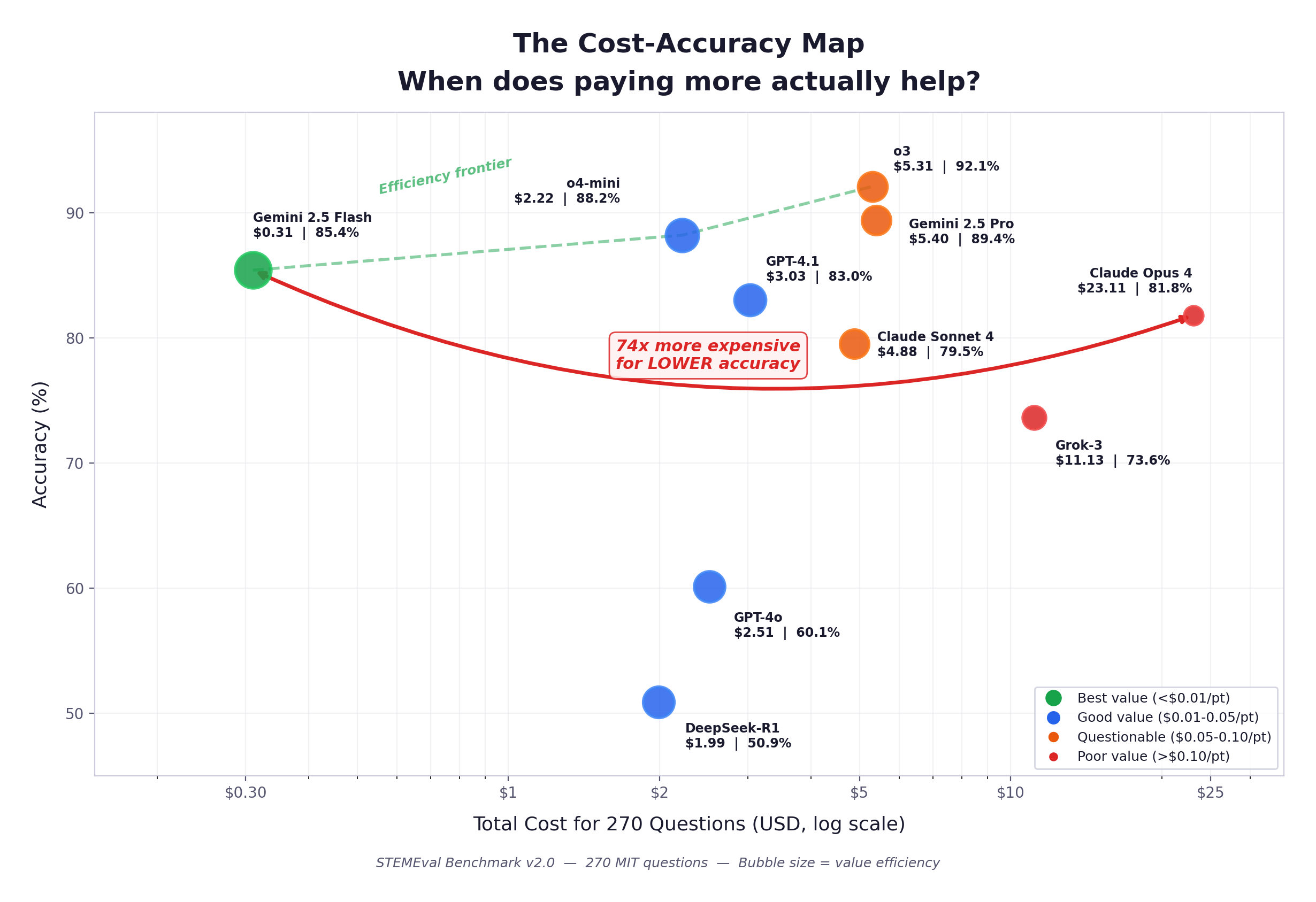
The 74x Cost Paradox
Gemini 2.5 Flash processed all 270 questions at a total cost of $0.31 and achieved an accuracy of 85.4%. Claude Opus 4 processed the same corpus at a total cost of $23.11 and achieved 81.8% accuracy. This represents a 74-fold cost differential in favour of the less expensive model, which also achieved a higher score, rendering the premium pricing economically indefensible on this evaluation.
| Model | Cost (full eval) | Accuracy | Cost per Accuracy Point | vs. Flash |
|---|---|---|---|---|
| Gemini 2.5 Flash | $0.31 | 85.4% | $0.004 | 1× |
| o4-mini | $2.22 | 88.2% | $0.025 | 7× |
| GPT-4o | $2.51 | 60.1% | $0.042 | 11× |
| GPT-4.1 | $3.03 | 83.0% | $0.037 | 10× |
| o3 | $5.31 | 92.1% | $0.058 | 16× |
| Claude Sonnet 4 | $4.88 | 79.5% | $0.061 | 17× |
| Grok-3 | $11.13 | 73.6% | $0.151 | 41× |
| Claude Opus 4 | $23.11 | 81.8% | $0.283 | 77× |
The cost-accuracy Pareto frontier has a well-defined structure. Gemini 2.5 Flash occupies the budget tier with a cost-per-accuracy-point of $0.004. o4-mini offers the most favourable balance of quality and expenditure among mid-tier models. o3 and Gemini 2.5 Pro justify their higher costs through genuine accuracy improvements over the rest of the field. The remaining models fall inside the frontier, meaning they are dominated on at least one dimension by a less expensive or more accurate alternative.
GPT-4o Is Inventing Physics
GPT-4o produced 11 hallucinated formulas across the evaluation corpus, generating equations that do not appear in physics and applying them with apparent confidence to problems for which they are inappropriate. On responses containing a hallucinated formula, the average score fell to approximately 1 out of 5, indicating that formula fabrication is not a minor perturbation but a near-total failure mode. No other quantitative failure was more reliably catastrophic.
Why this matters
GPT-4o remains the default model for ChatGPT’s free tier, the interface through which the majority of students interact with frontier AI. A model that fabricates physical equations and presents them confidently is not simply inaccurate; it is teaching students physics that does not exist. o3 and o4-mini produced zero hallucinated formulas across 270 questions, indicating that the failure is not inherent to the architecture but reflects choices made during training that have apparently been corrected in OpenAI’s more recent reasoning-oriented models.
| Model | Hallucinated Formulas | Outright Incorrect Answers | Refused to Answer |
|---|---|---|---|
| GPT-4o | 11 | 11 | 0 |
| Claude Sonnet 4 | 5 | 3 | 0 |
| Grok-3 | 4 | 9 | 0 |
| Claude Opus 4 | 2 | 2 | 0 |
| Gemini 2.5 Flash | 2 | 0 | 0 |
| Gemini 2.5 Pro | 1 | 0 | 0 |
| GPT-4.1 | 1 | 0 | 0 |
| o3 | 0 | 0 | 0 |
| o4-mini | 0 | 0 | 0 |
| DeepSeek-R1 | 0 | 0 | 123 |
DeepSeek-R1 exhibits a qualitatively distinct failure pattern. Rather than producing incorrect answers, it declined to respond to 123 of 270 questions, representing 45.6% of the evaluation corpus. No other model abstained more than three times. On the 147 questions it did attempt, DeepSeek-R1 reported an average confidence of 99.3% while achieving an accuracy of 50.9% — a 48-point miscalibration gap that is the largest observed in the study. The combination of widespread abstention and severe overconfidence on attempted questions suggests a fundamental limitation in the model’s capacity to sustain coherent multi-step reasoning over long derivations.
Physics Reveals What Algorithms Don’t
Disaggregating performance by course reveals a consistent and theoretically informative pattern. Models achieving the highest overall accuracy perform measurably better on algorithmic problems than on physics problems, whereas models in the lower half of the accuracy distribution perform worse on algorithms than on physics.
| Model | 8.033 Physics | 6.1220 Algorithms | Delta | Pattern |
|---|---|---|---|---|
| o3 | 90% | 97% | +7 | Strong reasoner |
| Gemini 2.5 Pro | 88% | 93% | +5 | Strong reasoner |
| o4-mini | 87% | 91% | +4 | Strong reasoner |
| GPT-4.1 | 83% | 82% | −1 | Balanced |
| Claude Opus 4 | 83% | 80% | −3 | Physics-first |
| Claude Sonnet 4 | 81% | 75% | −6 | Physics-first |
| GPT-4o | 64% | 51% | −13 | Both struggle |
| Grok-3 | 76% | 67% | −9 | Physics-first |
| DeepSeek-R1 | 55% | 44% | −11 | Both struggle |
We attribute this interaction to a structural difference between the two domains. Algorithm problems possess a formal, syntactic character that is well suited to the pattern recognition capabilities central to large language model training. Physics problems, by contrast, require the construction of an intuitive model of a physical situation and the creative selection of appropriate principles before any formal machinery can be applied. A model with only superficial competence can partially simulate physics performance through formula matching, retrieving equations that look appropriate for a given scenario without genuine understanding of their domain of validity. The same strategy fails on algorithm problems, where precise logical reasoning is non-negotiable and surface similarity provides insufficient guidance. This suggests that physics benchmarks may offer a more discriminating test of genuine reasoning ability than algorithm benchmarks alone.
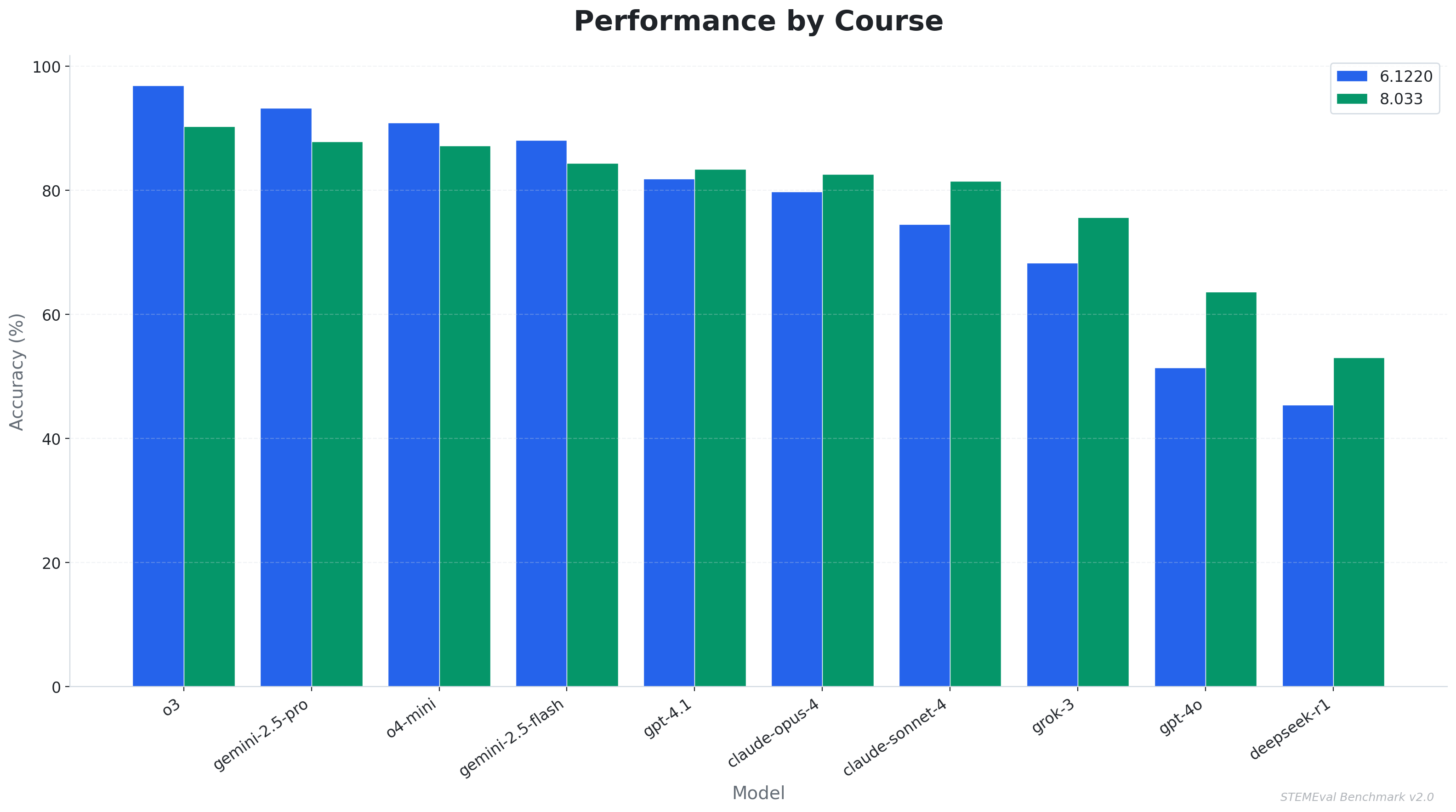
Physics benchmarks may constitute a more discriminating test of genuine machine reasoning than algorithmic benchmarks. The relativistic scenarios constructed for MIT 8.033 cannot be solved through memorization of surface patterns; they require an integrated understanding of physical principles and the ability to select among them appropriately. Algorithmic problems, by contrast, are susceptible to high performance through template recognition, which may overestimate a model’s underlying reasoning capability.
Rigor Is Structurally Load-Bearing
Responses were scored on two independent dimensions: correctness, ranging from 0 to 3 and reflecting the accuracy of the final answer, and rigor, ranging from 0 to 2 and reflecting whether the model articulated the derivation steps with appropriate mathematical reasoning. Rigor was not defined as mere verbosity but as the presence of logically ordered intermediate steps that would allow a reader to verify the reasoning independently.
The rank correlation between average rigor score and overall accuracy is near-perfect across all ten models:
| Model | Avg Rigor (0–2) | Accuracy |
|---|---|---|
| o3 | 1.95 | 92.1% |
| Gemini 2.5 Pro | 1.90 | 89.4% |
| o4-mini | 1.89 | 88.2% |
| Gemini 2.5 Flash | 1.85 | 85.4% |
| GPT-4.1 | 1.75 | 83.0% |
| Claude Sonnet 4 | 1.70 | 79.5% |
| Claude Opus 4 | 1.69 | 81.8% |
| Grok-3 | 1.45 | 73.6% |
| GPT-4o | 1.24 | 60.1% |
| DeepSeek-R1 | 1.01 | 50.9% |
This relationship is not coincidental. Generating intermediate derivation steps appears to exert a structural constraint on the model’s output: each step conditions the production of the next, reducing the degrees of freedom available for error accumulation. A model that writes “applying the Lorentz transformation to the rest frame of the observer” and then carries through the algebra is committing to a sequence of propositions that can each be verified in turn. A model that emits a final numerical answer without intermediate steps is, by contrast, producing output whose correctness is not internally constrained by prior commitments.
The pattern mirrors the pedagogical principle that asking students to show their work improves the quality of their thinking rather than merely documenting it. Across 2,700 AI-generated responses, the same structural relationship holds for machine-generated derivations.
Models Can Compute. They Can’t Think About Physics.
The most frequent error type across all ten models is the conceptual error, defined as a misidentification of which physical principle or framework the problem calls for, as opposed to a computational mistake made within an otherwise correct approach.
| Error Type | Count (all 10 models) | Avg Score When Error Occurs |
|---|---|---|
| Conceptual | 297 | ~1.9 / 5 |
| Algebraic | 156 | ~3.4 / 5 |
| Algorithmic | 136 | ~2.1 / 5 |
| Missing Steps | 80 | ~3.0 / 5 |
| Hallucinated Formula | 26 | ~1.1 / 5 |
Even o3, the highest-performing model in the evaluation, produced 20 conceptual errors compared to 14 algebraic errors. The distinction is significant for downstream trust. An algebraic error indicates that the model correctly identified the relevant physical framework and made an arithmetic or algebraic slip in execution — a class of mistake that is often recoverable by inspection. A conceptual error indicates that the model applied an inappropriate physical principle entirely: for example invoking classical momentum in a context requiring relativistic momentum, misidentifying the reference frame in which a quantity is measured, or constructing a solution to a different problem than the one posed. Such errors are not recoverable by checking the arithmetic; they require recognising that the foundational framing is wrong.
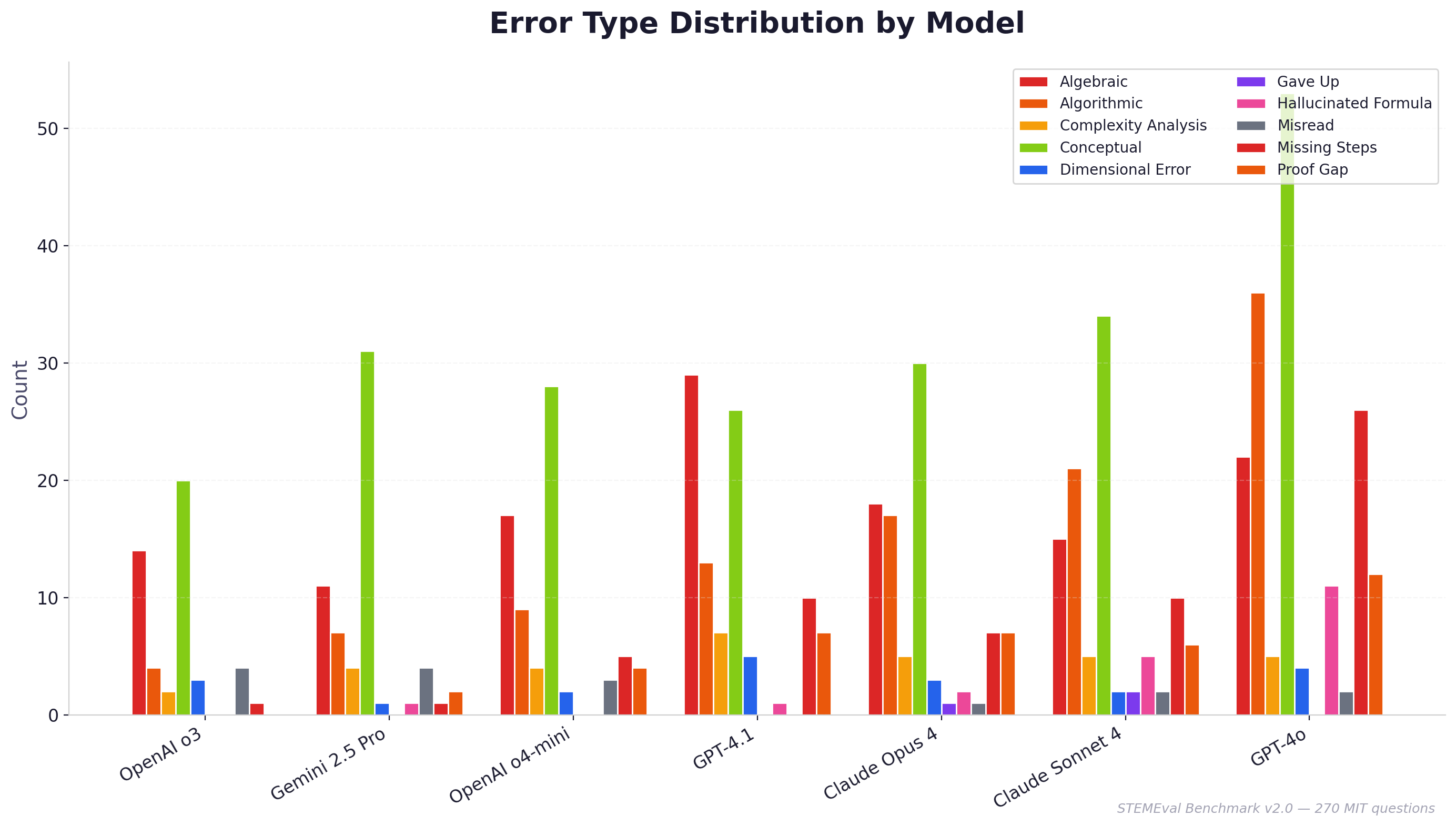

Conceptual understanding, rather than computational fluency, constitutes the primary bottleneck for frontier models on STEM reasoning tasks. This finding is in tension with the prevailing assumption that scaling model size and training compute is sufficient to improve technical reasoning; if conceptual errors dominate even at the frontier, the limitation appears to reside in the nature of how physical understanding is encoded during training rather than in the raw expressive capacity of the models.
Beyond Physics: AI as Essay Grader
The Essay Evaluation
We also evaluated all ten models on 102 student essays drawn from the Kaggle Automated Essay Scoring 2.0 dataset, curated by the Learning Agency Lab. Each model was asked to predict the human-assigned holistic score on a six-point scale. This component probes a qualitatively distinct trust question: whether AI judgement about subjective written work can be calibrated against the judgement of trained human raters, and whether models that exhibit strong quantitative reasoning also exhibit strong language-quality assessment.
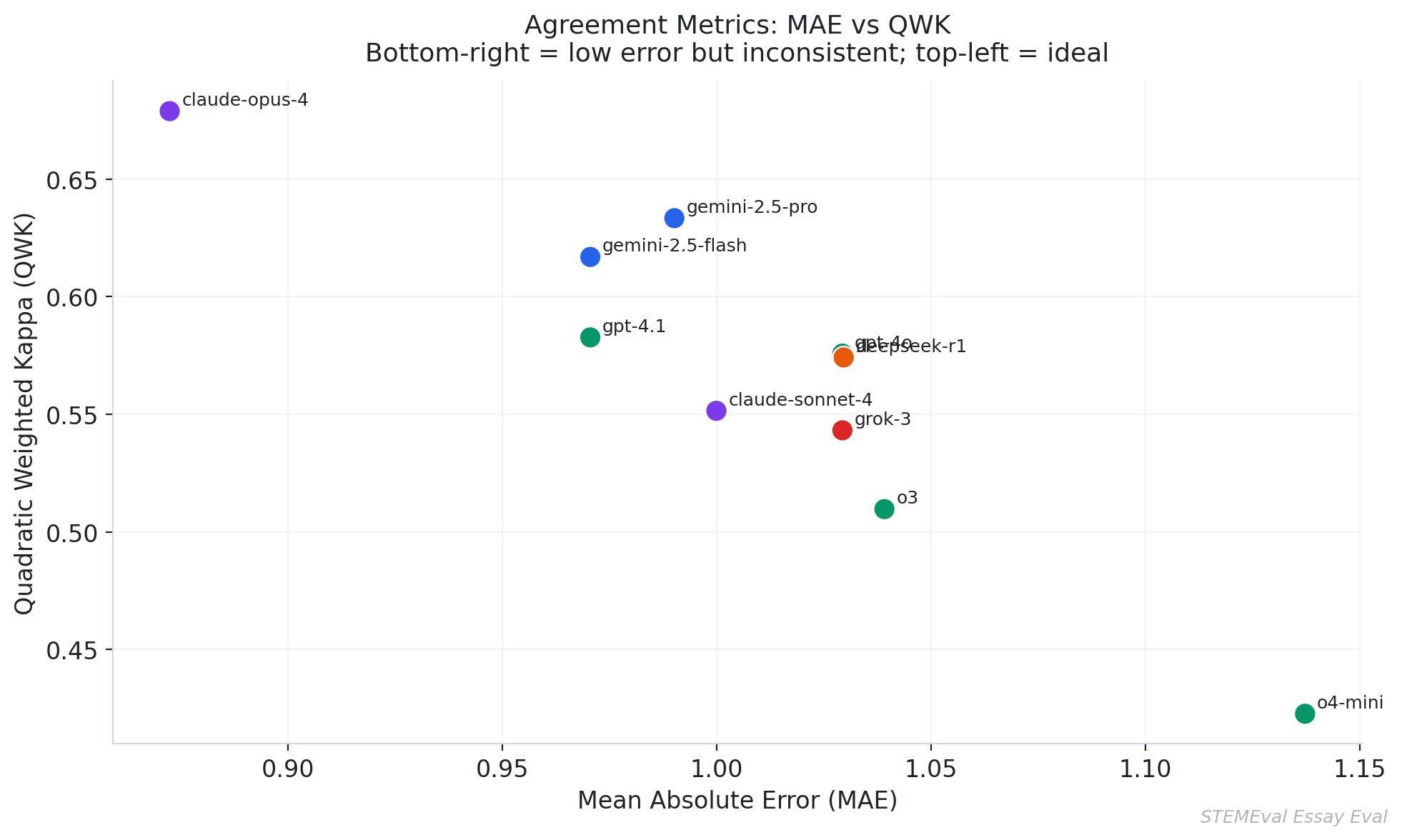
Essay evaluation employs different metrics than the physics benchmark. Quadratic Weighted Kappa (QWK) measures inter-rater agreement between model-assigned and human-assigned scores, weighting disagreements by the square of their magnitude so that large discrepancies are penalised more heavily than small ones. Mean Absolute Error (MAE) provides a complementary measure of average score deviation in raw units. Human-human inter-rater agreement on this dataset is approximately QWK = 0.74, representing the practical ceiling against which model performance should be interpreted.
| Model | QWK (↑ better) | MAE (↓ better) | Adjacent Accuracy | Cost |
|---|---|---|---|---|
| Claude Opus 4 | 0.679 | 0.87 | 85.3% | $2.69 |
| Gemini 2.5 Pro | 0.633 | 0.99 | 79.4% | $0.20 |
| Gemini 2.5 Flash | 0.617 | 0.97 | 76.5% | $0.02 |
| GPT-4.1 | 0.583 | 0.97 | 76.5% | $0.26 |
| GPT-4o | 0.576 | 1.03 | 72.6% | $0.34 |
| DeepSeek-R1 | 0.574 | 1.03 | 77.2% | $0.23 |
| Grok-3 | 0.543 | 1.03 | 73.5% | $0.42 |
| Claude Sonnet 4 | 0.552 | 1.00 | 76.5% | $0.53 |
| o3 | 0.510 | 1.04 | 69.6% | $0.46 |
| o4-mini | 0.423 | 1.14 | 65.7% | $0.29 |
Claude Opus 4 achieves the highest QWK of 0.679, remaining 0.06 below the human-human agreement threshold of 0.74. The rank ordering on essay quality is strikingly different from the physics rank ordering. o3, which leads the physics evaluation by a substantial margin, ranks ninth on essay grading with a QWK of 0.510. This reversal suggests that the capabilities underlying strong quantitative reasoning and those underlying reliable subjective writing assessment are meaningfully distinct, and that practitioners selecting models for language-quality tasks should not assume that physics or mathematics benchmarks are predictive.

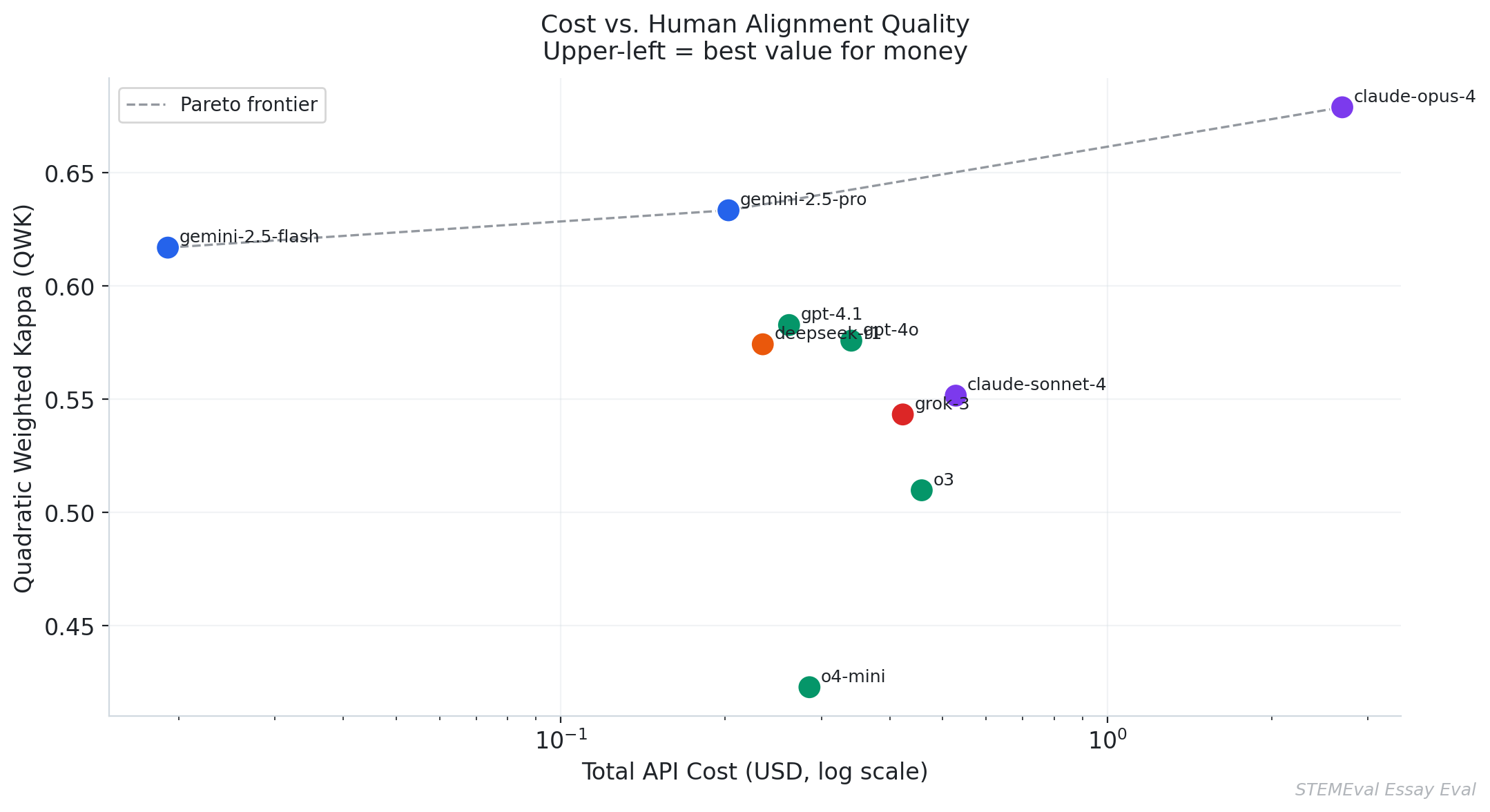
Gemini 2.5 Flash’s QWK of 0.617 at a total evaluation cost of $0.02 is a notable result on the cost-efficiency axis. For institutions in which the acceptable performance threshold falls between 0.60 and 0.65, and where budgetary constraints are acute, the Flash model represents an option that is economically transformative relative to alternatives costing an order of magnitude more for comparable agreement scores.
Why this matters for Trust
Automated essay scoring is among the highest-stakes AI deployment contexts in education, with scores directly affecting student progression, admissions decisions, and instructional feedback loops. These results demonstrate that no current model has reached human-level inter-rater agreement on this task. Any institution deploying AI essay scoring at scale carries an obligation to communicate the magnitude of this gap to students and educators, and to provide mechanisms through which assessments that fall in uncertain regions of the score distribution can be flagged and reviewed by a human rater.
What This Means for AI Trust
These findings bear directly on the problem that motivates Trust’s research programme. The central challenge in AI deployment is not establishing that models achieve acceptable average accuracy; it is enabling users to know, at the moment of an individual response, whether that particular output is reliable. Our results sharpen several dimensions of this problem.
Confidence scores are not trust signals
Nine of ten frontier models are systematically overconfident in technical domains. Any product that surfaces raw model confidence to users is, in the majority of cases, surfacing numbers that overstate reliability by between 5 and 48 percentage points. The practical consequence is that users who calibrate their reliance on AI output using stated confidence are operating on misleading information. Confidence calibration should be treated as the primary evaluation metric for any AI deployment, preceding accuracy in priority.
Error type matters as much as error rate
A model that produces algebraic errors on 20% of problems is qualitatively different from a model that produces conceptual errors on 20% of problems, even though their aggregate accuracy scores may be identical. Algebraic errors are recoverable: a careful reader can often identify a dropped factor or sign error and correct for it. Conceptual errors are expressed with the same surface confidence as correct responses, are coherent and internally consistent, and are wrong in ways that are not detectable without independent domain expertise. The error taxonomy developed for this benchmark provides a framework for making this distinction operationally tractable.
Model selection is inherently domain-specific
The model achieving the highest accuracy on physics reasoning ranks ninth on essay grading. The model with the most favourable cost-accuracy ratio for structured quantitative tasks is not the most cost-efficient option for subjective language assessment. Decisions about which model to deploy should be made at the level of the specific task and evaluation criteria, not at the level of a general-purpose leaderboard score. There is no universally best model; there is only the best model for a given deployment context and a given definition of acceptable performance.
The consistency floor is an independent reliability dimension
o3 and o4-mini produced no zero-scored responses across 270 MIT-level questions. GPT-4o produced 11 outright failures. For a wide range of applications, a model that reliably produces partially correct output is more trustworthy in practice than a model with a higher average accuracy but a non-negligible probability of catastrophic failure on any given query. Mean accuracy does not capture this distribution, and evaluations that report only mean performance may substantially misrepresent the reliability profile of the systems they describe.
Methodology
Physics and algorithms evaluation. The question corpus comprised 270 items extracted from official problem sets, practice examinations, and midterm examinations from MIT 8.033 (Special and General Relativity, Fall 2025) and 6.1220 (Design and Analysis of Algorithms, Fall 2023). Each model received a single-turn prompt consisting of the question text and the official course formula sheet, with instructions to show derivation steps and report a scalar confidence estimate. No multi-turn interaction, retrieval tools, or external computation were permitted. Responses were evaluated by an automated grading judge implemented using Claude Sonnet, which scored correctness on a 0 to 3 scale and mathematical rigor on a 0 to 2 scale for each response, benchmarked against official solution keys.
Essay evaluation. One hundred and two essays were sampled from the Kaggle Automated Essay Scoring 2.0 dataset, curated by the Learning Agency Lab, with stratified sampling yielding 17 essays at each of the six score levels. Each model was asked to predict the human-assigned holistic score as a single integer from 1 to 6. Inter-rater agreement between model predictions and human labels was measured using Quadratic Weighted Kappa and Mean Absolute Error.
Models evaluated. o3, o4-mini, GPT-4.1, and GPT-4o from OpenAI; Gemini 2.5 Pro and Gemini 2.5 Flash from Google DeepMind; Claude Opus 4 and Claude Sonnet 4 from Anthropic; Grok-3 from xAI; and DeepSeek-R1 from DeepSeek.
Cost accounting. Total API expenditure was tracked per model, including both input and output token costs at published rates prevailing at the time of evaluation in March 2026. Per-accuracy-point cost was computed by dividing total cost by the percentage accuracy on the physics and algorithms benchmark.
Cite this post
@misc{trust2026stemeval,
author = {Trust Research},
title = {Can You Trust AI with a MIT Exam? STEMEval Benchmark v2.0},
year = {2026},
month = {March},
url = {https://www.trytrust.ai/research/stemeval}
}